Contemporary bathymetric data collection techniques are capable of collecting sub-meter resolution data to ensure full seafloor-bottom coverage for safe navigation as well as to support other various scientific uses of the data. Moreover, bathymetry data are becoming increasingly available. Datasets are compiled from these sources and used to update Electronic Navigational Charts (ENCs), the primary medium for visualizing the seafloor for navigation purposes, whose usage is mandatory on Safety Of Life At Sea (SOLAS) regulated vessels. However, these high-resolution data must be generalized for products at scale, an active research area in automated cartography. Algorithms that can provide consistent results while reducing production time and costs are increasingly valuable to organizations operating in time-sensitive environments. This is particularly the case in digital nautical cartography, where updates to bathymetry and locations of dangers to navigation need to be disseminated as quickly as possible. Therefore, this research covers the development of cartographic constraint-based generalization algorithms operating on both Digital Surface Model (DSM) and Digital Cartographic Model (DCM) representations of multi-source composite bathymetric data to produce navigationally-ready datasets for use at scale.
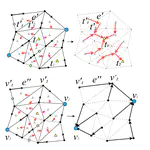
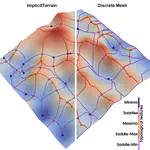
Similarly, many coastal data analysis applications utilize unstructured meshes for representing terrains due to the adaptability, which allows for better conformity to the shoreline and bathymetry. Finer resolution along narrow geometric features, steep gradients, and submerged channels, and coarser resolution in other areas, reduces the size of the mesh while maintaining a comparable accuracy in subsequent processing. Generally, the mesh is constructed a priori for the given domain and elevations are interpolated to the nodes of the mesh from a predefined digital elevation model. Mesh simplification is a technique used in computer graphics to reduce the complexity of a mesh or surface model while preserving features such as shape, topology, and geometry. This technique can be used to mitigate issues related to processing performance by reducing the number of elements composing the mesh, thus increasing efficiency. The primary challenge is finding a balance between the level of generalization, preservation of specific characteristics relevant to the intended use of the mesh, and computational efficiency. Despite the potential usefulness of mesh simplification for reducing mesh size and complexity while retaining morphological details, there has been little investigation regarding the application of these techniques specifically to Bathymetric Surface Models (BSMs), where additional information such as vertical uncertainty can help guide the process. Toward this effort, this research also explores the effects of BSM mesh simplification on a coastal ocean model forced by tides in New York Harbor.